library(tidyverse)
library(tidymodels)
stocks <- read_csv("stocks.csv")Regression with one predictor
Regression with a single predictor
Data and packages
We’ll work with data on Apple and Microsoft stock prices and use the tidyverse and tidymodels packages. The data for lecture was originally gathered using the tidyquant R package. It features Apple and Microsoft stock prices from January 1st 2020 to December 31st 2021.
Simple regression model and notation
\[ y = \beta_{1} + \beta_1 x + \epsilon \]
\(y\): the outcome variable. Also called the “response” or “dependent variable”. In prediction problems, this is what we are interested in predicting.
\(x\): the predictor. Also commonly referred to as “regressor”, “independent variable”, “covariate”, “feature”, “the data”.
\(\beta_0\), \(\beta_1\) are called “constants” or coefficients. They are fixed numbers. These are population parameters. \(\beta_0\) has another special name, “the intercept”.
\(\epsilon\): the error. This quantity represents observational error, i.e. the difference between our observation and the true population-level expected value: \(\beta_0 + \beta_1 x\).
. . .
Effectively this model says our data \(y\) is linearly related to \(x\) but is not perfectly observed due to some error.
Stock prices of Microsoft and Apple
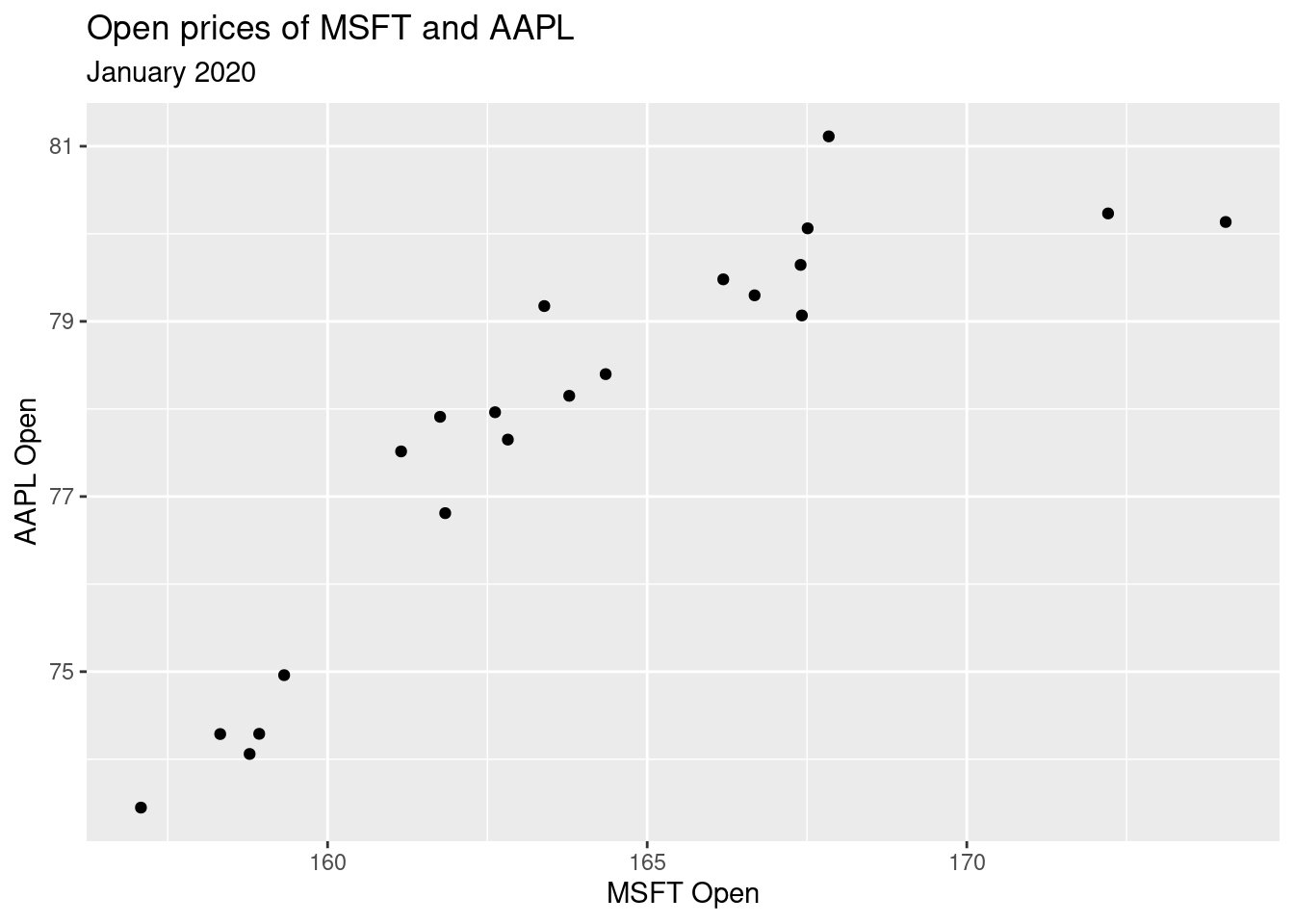
Let’s examine January 2020 open prices of Microsoft and Apple stocks to illustrate some ideas.
stocks_jan2020 <- stocks |>
filter(month(date) == 1 & year(date) == 2020)
ggplot(stocks_jan2020, aes(x = MSFT.Open, y = AAPL.Open)) +
geom_point() +
labs(
x = "MSFT Open",
y = "AAPL Open",
title = "Open prices of MSFT and AAPL",
subtitle = "January 2020"
)
Fitting “some” model
Before we get to fitting the best model, let’s fit “some” model, say with slope = -5 and intercept = 0.5.
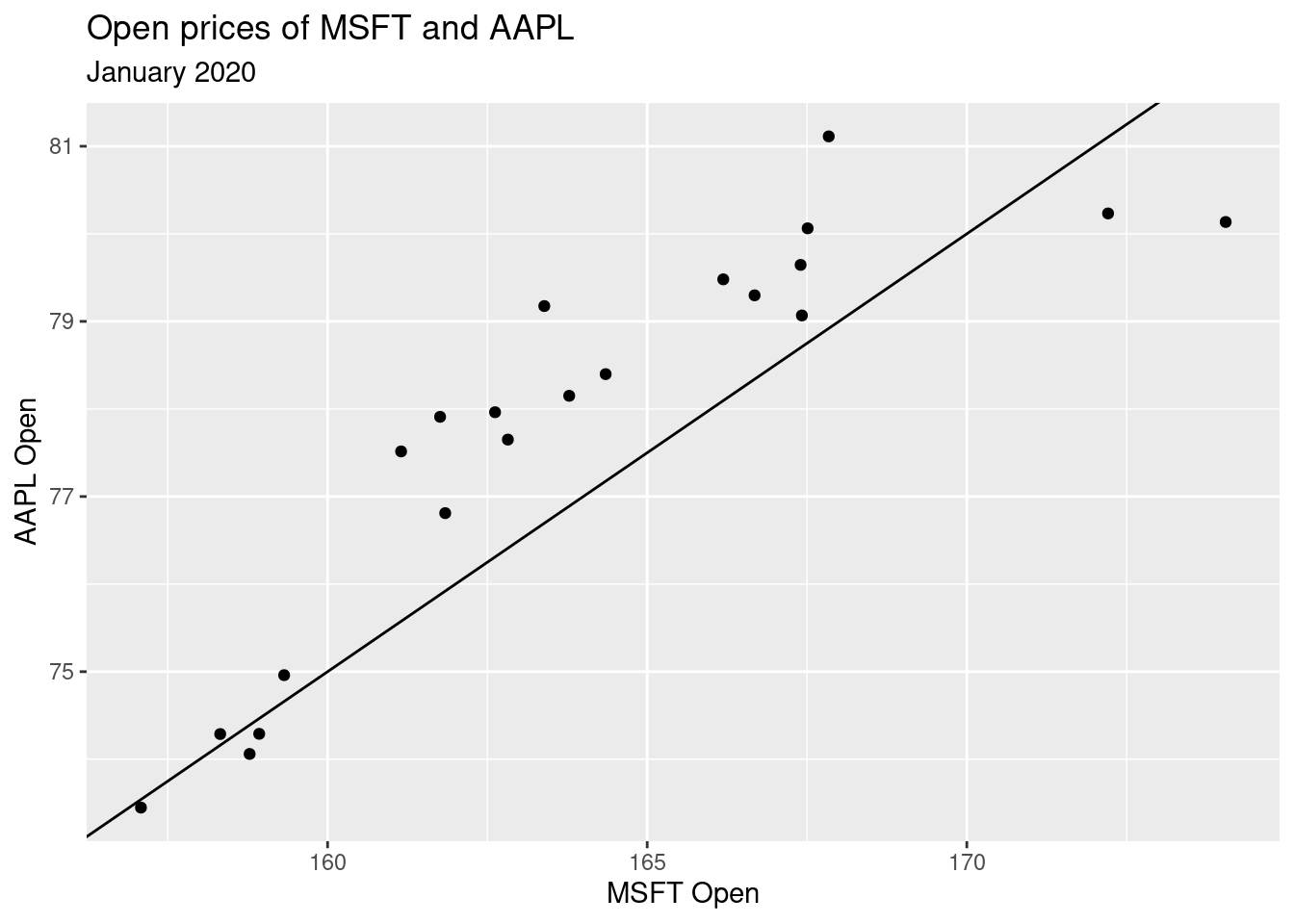
Fitting “some” model
\[ \hat{y} = \hat{\beta}_0 + \hat{\beta}_1 ~ x \\ \hat{y} = -5 + 0.5 ~ x \]
- \(\hat{y}\) is the expected outcome
- \(\hat{\beta}\) is the estimated or fitted coefficient
- There is no error term here because we do not predict error
Populations vs. samples
Population:
\[ y = \beta_0 + \beta_1 ~ x \]
Samples: \[ \hat{y} = \hat{\beta_0} + \hat{\beta_1} ~ x \]
- The central idea is that if we measure every \(x\) and every \(y\) in existence, (“the entire population”) there is some true “best” \(\beta_0\) and \(\beta_1\) that describe the relationship between \(x\) and \(y\)
- Since we only have a sample of the data, we estimate \(\beta_0\) and \(\beta_1\)
- We call our estimates \(\hat{\beta_0}\), \(\hat{\beta_1}\) “beta hat”. We never have all the data, thus we never can really know what the true \(\beta\)s are
Residuals
- For any linear equation we write down, there will be some difference between the predicted outcome of our linear model (\(\hat{y}\)) and what we observe (\(y\))… (But of course! Otherwise everything would fall on a perfect straight line!)
This difference between what we observe and what we predict \(y - \hat{y}\) is known as a residual, \(e\).
More concisely,
\[ e = y - \hat{y} \]
A residual, visualized
Residuals are dependent on the line we draw. Visually, here is a model of the data, \(y = -5 + 0.5 ~ x\) and one of the residuals is outlined in red.
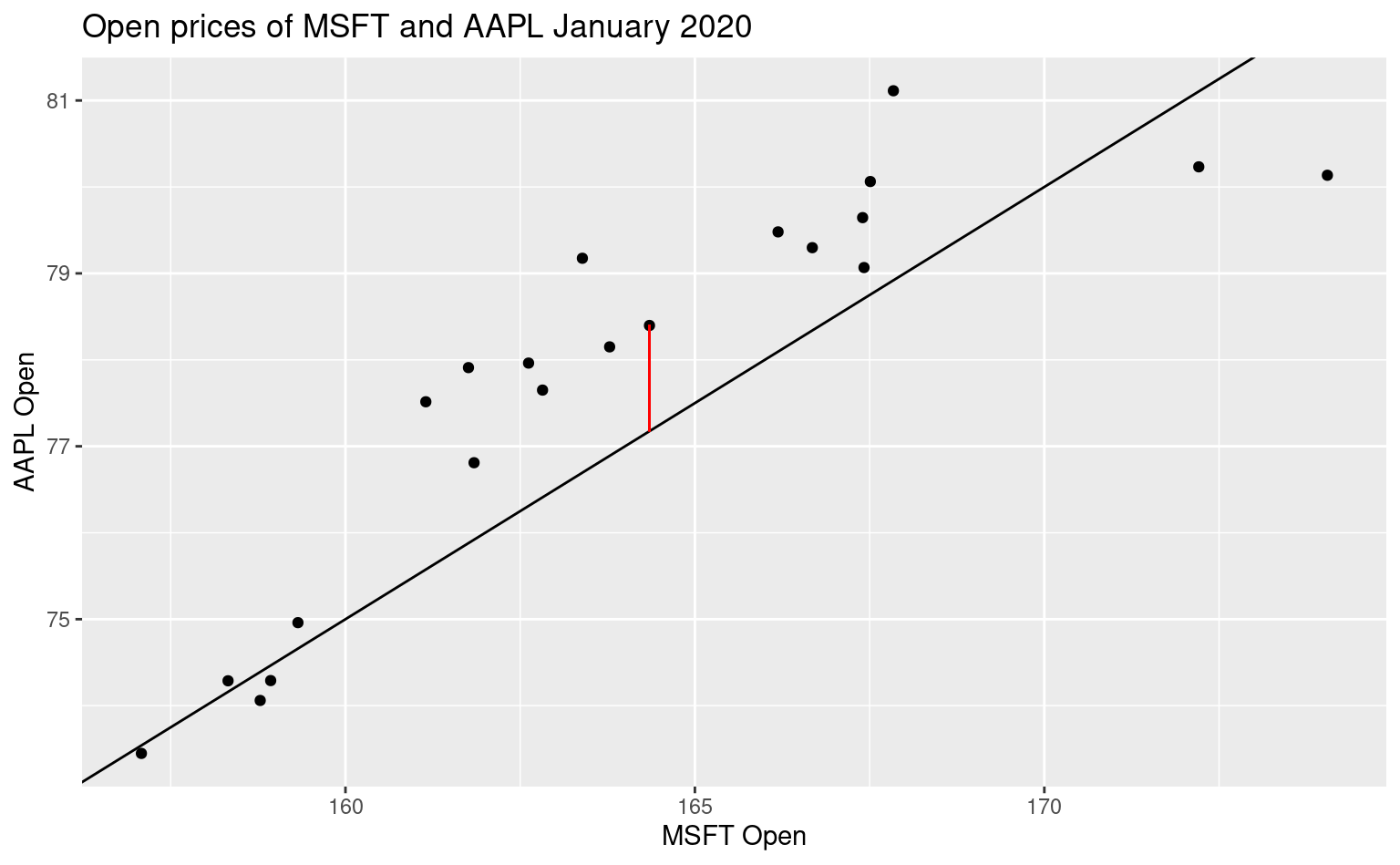
All residuals, visualized
There is, in fact, a residual associated with every single point in the plot.

Minimize residuals
We often wish to find a line that fits the data “really well”, but what does this mean? Well, we want small residuals! So we pick an objective function. That is, a function we wish to minimize or maximize.
Today we’ll explore the question “How do stock prices of Apple and Microsoft relate to each other?”
Goals
Understand the grammar of linear modeling, including \(y\), \(x\), \(\beta\), \(e\) fitted estimates and residuals
Add linear regression plots to your 2D graphs
Write a simple linear regression model mathematically
Fit the model to data in R in a
tidyway
Models and residuals
Exercise 1
At first, you might be tempted to minimize \(\sum_i e_i\), the sum of all residuals, but this is problematic. Why? Can you come up with a better solution (other than the one listed below)?
Large positive and negative residuals could cancel out.
We could minimize the sum of absolute values.
Minimize the sum of squared residuals
In practice, we minimize the sum of squared residuals:
\[ \sum_i e_i^2 \]
Note, this is the same as
\[ \sum_i (y_i - \hat{y}_i)^2 \]
Exercise 2
Check out an interactive visualization of “least squares regression” here. Click on I and drag the points around to get started. Describe what you see.
Each square is a “square residual”. The line minimizes the sum of squared residuals, (i.e. it minimizes the total area of squares we see on the screen).
This is called “Ordinary Least Squares” (OLS) regression.
Plotting the least squares regression line
Plotting the OLS regression line, that is, the line that minimizes the sum of square residuals takes one new geom. Simply add
geom_smooth(method = "lm", se = FALSE)to your plot.
method = "lm" says to draw a line according to a “linear model” and se = FALSE turns off standard error bars. You can try without these options for comparison.
Optionally, you can change the color of the line, e.g.
geom_smooth(method = "lm", se = FALSE, color = "red")Exercise 4
In the slides we fit a model with slope 0.5 and intercept -5. The code for layering the line that represents the model over your data is given below. Add geom_smooth() as described above with color = "steelblue" to see how close your line is.
ggplot(stocks_jan2020, aes(x = MSFT.Open, y = AAPL.Open)) +
geom_point() +
geom_abline(slope = 0.5, intercept = -5) +
geom_smooth(method = "lm", se = F, color = "steelblue") +
labs(
x = "MSFT Open",
y = "AAPL Open",
title = "Open prices of MSFT and AAPL",
subtitle = "January 2020"
)`geom_smooth()` using formula = 'y ~ x'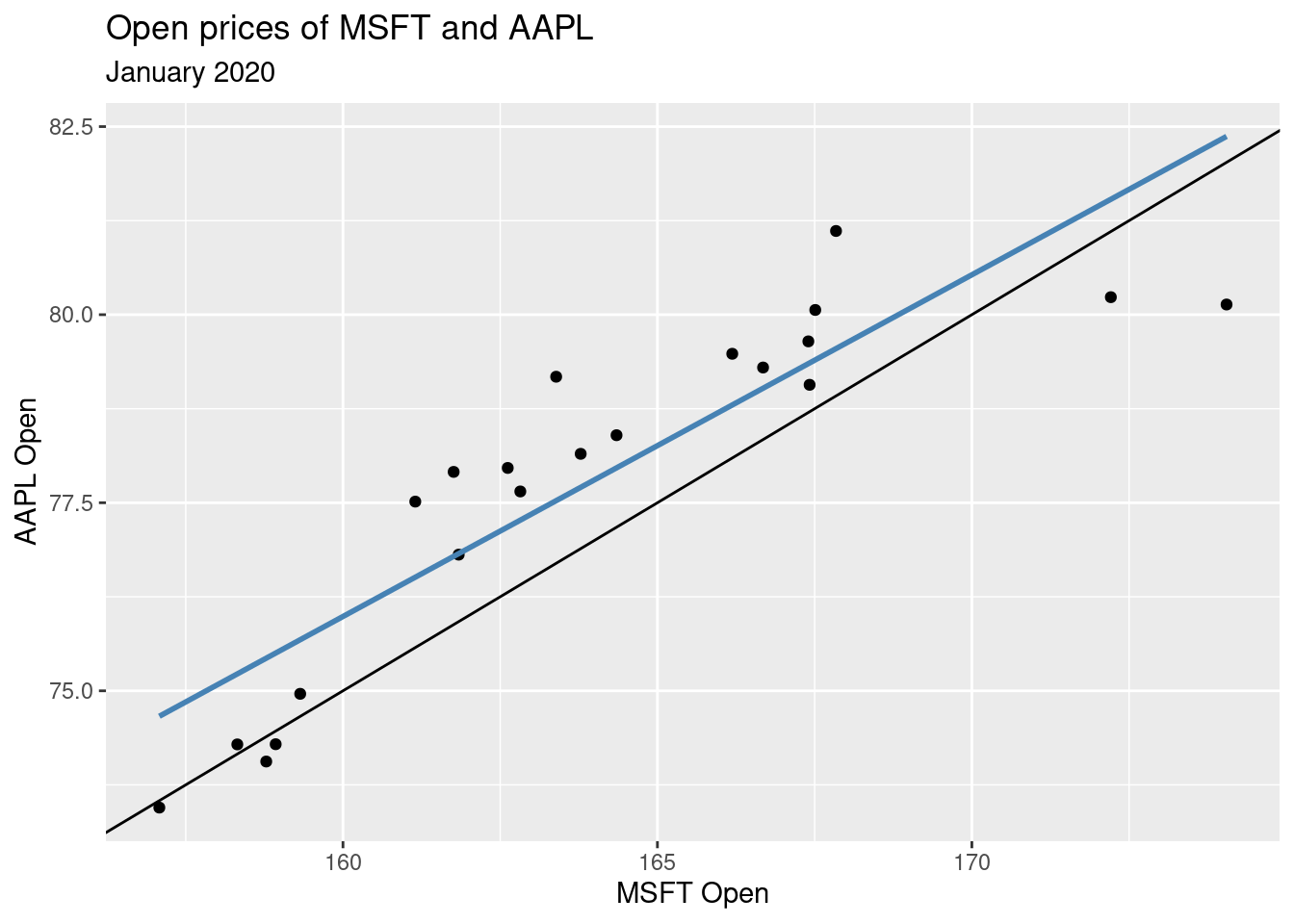
Finding \(\hat{\beta}\)
To fit the model in R, i.e. to “find \(\hat{\beta}\)”, use the code below as a template:
model_fit <- linear_reg() |>
fit(y ~ x, data = dataframe)linear_regtellsRwe will perform linear regressionfitdefines the outcome \(y\), predictor \(x\) and the data set
Running the code above, but replacing the arguments of the fit command appropriately will create a new object called model_fit that stores all information about your fitted model.
To access the information, you can run, e.g.
tidy(model_fit)Let’s try it out.
Exercise 5
Find the least squares line \(y = \hat{\beta_0} + \hat{\beta_1} x\) for January 2020, where \(x\) is Microsoft’s opening price and \(y\) is Apple’s opening price. Display a tidy summary of your model.
mic_app_fit <- linear_reg() |>
fit(AAPL.Open ~ MSFT.Open, data =stocks_jan2020)
tidy(mic_app_fit)# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.31 8.87 0.373 0.713
2 MSFT.Open 0.454 0.0541 8.40 0.0000000808Exercise 6
Re-write the fitted equation replacing \(\hat{\beta}_0\) and \(\hat{\beta}_1\) with the estimates from the model you fit in the previous exercise.
\[ \hat{y} = 3.31174 + 0.45423 x \]
where \(\hat{y}\) is the predicted Apple open price and \(x\) is the open price of Microsoft.
\(\hat{\beta}_0 = 3.31174\) and \(\hat{\beta}_1 = 0.45423\).
Exercise 7
Interpret \(\hat{\beta}_0\) and \(\hat{\beta}_1\) in context of the data.
\(\hat{\beta}_0 = 3.31174\) is the price of Apple if Microsoft opened at 0.
\(\hat{\beta}_1 = 0.45423\) : for every dollar increase in Microsoft open price, we expect Apple open price to increase by 0.45423.
Bonus exercise
Say Microsoft opens at 166 dollars. What do I predict the opening price of AAPL to be?
\[ \hat{y} = 3.31174 + 0.45423 * 166 \]
yhat <- 3.31174 + 0.45423*166
yhat[1] 78.71392